Trying to build an Anime Portrait Disocclusion model-Part 1: Simple Autoencoder
Introduction
Since around Junior year of Highschool(around 2020), I have been trying to build an AI based method to automate the rigging process of Live2D models, especially for VTubers.

Until last year, the direction I took was close to other projects that tried something similar like Pramook Khungurn’s Talking Head Anime from a Single Image or AnimeCeleb. Both models receive an input of a base image (an image of an anime face) and a desired pose(information such as orientation of the head, expression of the face) and generates an image of the face following the desired pose.
While these models achieve high performance already, for them to be used in VTubing, the model must generate each frame in real time, which many, myself included, do not have the strong enough computer to do.
Last year, I thought of a different approach where the model does not generate each frame in real time, but a rigged Live2D model from a base image instead. That way, the model only has to run once and the generated Live2D model can be used while streaming without AI.
To elaborate, many animated VTuber models use what is called Live2D models, where different parts of an image is rigged, layered, and divided into meshes so they can be animated by moving said meshes.

This process of “Rigging” a Live2D model is both time-consuming and skill-intensive, not to mention that you require a special form of drawing to serve as the texture of the model before you can start rigging in the first place. The drawing must be divided into different layers of the model and each layer must be divided into different parts for the model to move naturally.

While my final goal is to create a model that receives a single image and outputs a fully-rigged Live2D model complete with divided layers, parts, set meshes, and calibrated parameters, for now I wanted to focus on dividing the layer part.
So, my goal for this series is this: Create an AI model that receives an image of an anime character, and outputs multiple images that each correspond to different parts of the character such as their face, hair, eyes, clothes, etc.
Data
While researching, I have found a database of Live2D models from different games on github: https://github.com/Eikanya/Live2d-model. For now, I have only used the Live2D models from the game ‘BangDream!’. You will see how this caused a problem. Later on I plan to expand this project to different art styles.
I have also found a tool that outputs different part of the model as an image and organizes them into different layers(face, arm, eyes, clothes, etc.): https://github.com/jeffshee/live2d/tree/master.
Using this, I was able to scrape hundreds of portrait images of anime characters and images that only contain certain parts of the face.

As you can see above, in the original image, some parts of a certain layer could be covering some parts of another layer. For example, the front-hair layer covers part of the face layer. I want my model to fill in the part of the character’s eye that wasn’t seen in the original image. This is why the title of the article is called ‘Disocclusion model’.
You can download the current dataset from this google drive link: https://drive.google.com/drive/folders/1O6xG1q0okhKULSFdFV1G8mEFbRCLcdYo?usp=sharing
Model
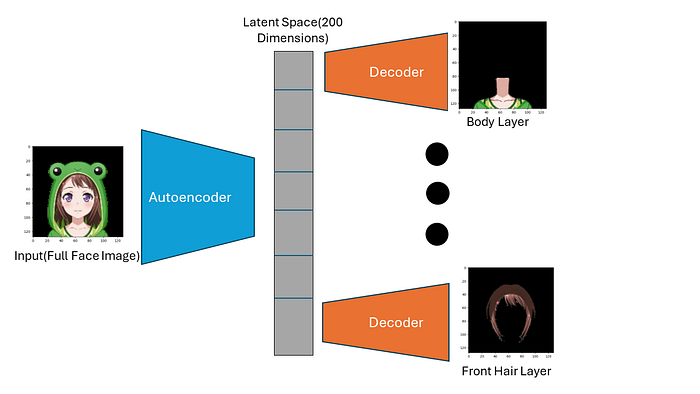
The model architecture I chose is the Convolutional Autoencoder and decoder model.
First, the model Receives input of the full character image. The full character image is fed into an autoencoder. The autoencoder then outputs a latent space representation of the image in the form of a 200-dimension latent space vector. The vector is divided into 8 parts, each part corresponding to each layers, and fed into a decoder. The decoder then outputs an image for each layer. All the decoders share the same weights. This is because I plan to use the same latent space representation to generate the meshes as well.
Below is the code I used to make the model in Keras.
from keras.models import Model, Sequential
from keras.layers import Conv2D, MaxPooling2D, Input, ZeroPadding2D, Dropout, Conv2DTranspose, Cropping2D, Add, Dense, Flatten, Reshape, Lambda
import tensorflow as tf
channels, width, height = 3, 128, 128
def make_autoencoder(latent_dim=200):
input_shape = (height, width, channels, )
input = Input(name="autoencoder_input",shape=input_shape)
conv1 = Conv2D(filters=64,kernel_size=(3,3),padding="same", activation="relu", name="conv1")(input)
maxpool1 = MaxPooling2D(pool_size=(2,2),strides=(2,2), name="maxpool1")(conv1)
conv2 = Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu", name="conv2")(maxpool1)
maxpool2 = MaxPooling2D(pool_size=(2,2),strides=(2,2), name="maxpool2")(conv2)
conv3_1 = Conv2D(filters=256, kernel_size=(3,3), padding="same", name="conv3_1")(maxpool2)
conv3_2 = Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu", name="conv3_2")(conv3_1)
maxpool3 = MaxPooling2D(pool_size=(2,2),strides=(2,2), name="maxpool3")(conv3_2)
conv4_1 = Conv2D(filters=512, kernel_size=(3,3), padding="same", name="conv4_1")(maxpool3)
conv4_2 = Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu", name="conv4_2")(conv4_1)
maxpool4 = MaxPooling2D(pool_size=(2,2),strides=(2,2), name="maxpool4")(conv4_2)
conv5_1 = Conv2D(filters=512, kernel_size=(3,3), padding="same", name="conv5_1")(maxpool4)
conv5_2 = Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu", name="conv5_2")(conv5_1)
maxpool5 = MaxPooling2D(pool_size=(2,2),strides=(2,2), name="maxpool5")(conv5_2)
flatten = Flatten(name="flatten")(maxpool5)
latent_twice = Dense(latent_dim*2, name="latent_twice")(flatten)
output = Dense(latent_dim, name="latent")(latent_twice)
return Model(input, output)
def make_single_decoder(latent_dim=200, name='0'):
model = Sequential()
print('latent_dim:',latent_dim)
latent_in = Input(shape=(latent_dim,), name=name+"_latent_in")
latent_twice = Dense(latent_dim*2, name=name+"_latent_twice")(latent_in)
dense1 = Dense(8192, name=name+"_dense1")(latent_twice)
reshape = Reshape((4,4,512))(dense1)
deconv1_1 = Conv2DTranspose(filters = 512, kernel_size=(3,3), strides=2, padding="same", activation="relu", name=name+"_deconv1_1")(reshape)
deconv1_2 = Conv2D(filters = 512, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv1_2")(deconv1_1)
deconv2_1 = Conv2DTranspose(filters = 512, kernel_size=(3,3), strides=2, padding="same", activation="relu", name=name+"_deconv2_1")(deconv1_2)
deconv2_2 = Conv2D(filters = 512, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv2_2")(deconv2_1)
deconv3_1 = Conv2DTranspose(filters = 256, kernel_size=(3,3), strides=2, padding="same", activation="relu", name=name+"_deconv3_1")(deconv2_2)
deconv3_2 = Conv2D(filters = 256, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv3_2")(deconv3_1)
deconv4_1 = Conv2DTranspose(filters = 128, kernel_size=(3,3), strides=2, padding="same", activation="relu", name=name+"_deconv4_1")(deconv3_2)
deconv4_2 = Conv2D(filters = 128, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv4_2")(deconv4_1)
deconv5_1 = Conv2DTranspose(filters = 64, kernel_size=(3,3), strides=2, padding="same", activation="relu", name=name+"_deconv5_1")(deconv4_2)
deconv5_2 = Conv2D(filters = 64, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv5_2")(deconv5_1)
deconv6_1 = Conv2DTranspose(filters=3, kernel_size=(3,3), strides=1, padding="same", activation="relu", name=name+"_deconv6_1")(deconv5_2)
output = Conv2D(filters = channels, kernel_size=(3,3), strides=1, padding="same", name=name+"_deconv6_2")(deconv6_1)
return Model(latent_in, output)
def make_full_model(latent_dim = 200):
img_input = Input(name="img_input", shape=(width, height,channels))
encoder_model = make_autoencoder(latent_dim)
encoder = encoder_model(img_input)
decoder_models = []
lambda_layer = Lambda(lambda x: tf.split(x,num_or_size_splits=8,axis=1))
split_tensors = lambda_layer(encoder)
decoder_model = make_single_decoder(latent_dim//8, '0')
for split_encoder in split_tensors:
dec = decoder_model(split_encoder)
decoder_models.append(dec)
return Model(inputs=img_input, outputs=decoder_models)Training&Result
For training I used the Adam optimizer with the learning rate of 0.00005 and Mean Square Error loss.
I had it start training and after a while the validation loss stopped decreasing so I stopped the training and had it output on a test image.

While very blurry, I was ecstatic to see that the model learned which layer corresponds with which part of the face pretty well. It was also a plus that the model seemed to be able to fill in parts of the layer that are obscured by other layers pretty well. For example, the center part of the back hair layer and the face Layer are pretty well filled in even though they are obscured in the input image. I was especially happy to see that the model did a good job with the hair layers.
Problem
After seeing this, I was curious if it was possible that the model could separate non-BangDream! character images as well, understanding characters of the drawing-style that it has not been trained on. So I inputted a random anime character profile into the model.

I did not expect much but the result showed a underlying problem in the training dataset. Because all the BangDream! characters have their face, hair, body, eye, mouth in the same positions, the model did not learn to look at the inputted image and figure out which part is which, and just memorized each part’s position in the image instead.
Possible Solutions/Improvements
For the problem of the model memorizing the image positions instead of actually looking at the inputted image, I have three possible solutions:
- Randomly move around the images in the training data, so the model cannot learn the positions.
- Attach a pre-trained Anime Face Image Segmentation network on top of the autoencoder. Have the encoder receive both the original image and the segmentation result and output the latent representation with both in mind.
- Use different drawing styles from Live2D models of different games as training dataset. This may take a while because other models have different ways of labelling and dividing layers in a model(for example, BangDream! models have separate ‘front hair’ and ‘back hair’ layers but other models have one ‘hair’ layer.)
As for the problem of the model output being blurry, I have four possible solutions:
- Make the latent space bigger.
- Make the autoencoder and decoder bigger.
- Change the Autoencoder architecture into UNet.
- Change the Autoencoder architecture into Variational Autoencoder.
Also, I would like to be able to train the model on images that are not Live2D models and just images, with two types of custom loss: reconstruction loss(how close the image is to the original if you overlap each layer on top?) and style loss(how natural do the filled-in parts of the layer images look?). These probably require a GAN style architecture but I don’t know if they will work. Probably will try later.
Conclusion
I wish to build a somewhat-working version of this project before mid-July because I have a personal event going on then.
Any feedback are welcome! Please leave a comment or send an email to andrewsoncha2@gmail.com to leave feedback.
